Case Study
Advisor Intelligence MCP
A real-time financial advisor sentiment intelligence layer, served through the Model Context Protocol so any LLM can query it in natural language.
The wealth-tech industry runs on annual research cycles, but advisor sentiment moves faster than annual reports. I built a structured intelligence layer that converts public advisor conversation into queryable data — and served it through MCP, so any LLM can reason over it live.
The Problem
Advisor sentiment moves faster than annual reports.
The wealth management industry runs on annual research cycles. Cerulli, Aite-Novarica, and similar firms publish once a year. Advisor sentiment doesn't wait.
Wealth-tech vendors making product decisions, RIA strategy teams evaluating competitive position, practice management leaders thinking about adoption — all of them are working from data that's at least twelve months stale. The landscape they're navigating doesn't look like that data anymore.
The question I kept coming back to was simple: what are advisors actually saying, right now, about the tools they use every day? That question didn't have a clean answer anywhere. So I built one.
The Insight
Public conversation is structured data waiting to happen.
Advisors are already talking publicly — on G2, industry forums, LinkedIn, Reddit. The gap was never data availability. It was structure and accessibility. The moment I framed it that way, the project shifted from "scrape some data" to "build a structured intelligence layer." Everything downstream — the schema, the categorization, the serving layer — followed from that reframe.
The Approach
Validation before build.
I made every decision on this project trying to avoid the trap that kills most data products: building infrastructure before validating signal. Schema first, manual annotation before automation, narrow vendor list before broad expansion. Each step earned the next one.
Locked the 14-field schema first
I defined the data schema before collecting a single review. Identity, content, categorization, signal, annotation — five logical groups, fourteen fields. Locking this early meant every downstream decision had a clear contract to work against. Schema drift is what kills these projects.
Chose G2 as the starting data source
Software review platforms give me three things at once: signal density, structured fields, and legal defensibility. Public reviews on G2 are written by real advisors evaluating real tools. I wasn't trying to maximise volume — I was trying to maximise per-row usefulness.
Narrowed to 5 vendors
Redtail CRM, Wealthbox, Salesforce Financial Services Cloud, eMoney, and MoneyGuidePro. Five vendors covers the practical surface area of advisor daily workflow without diluting the analysis. Expanding later is straightforward. Expanding too early would have made every other decision harder.
Manual annotation before automation
I annotated the first batch by hand to build a codebook — what counts as a compliance concern, how to distinguish vendor frustration from platform frustration, when sentiment is genuinely negative versus performative. Automating before I had that codebook would have just encoded my early misreadings at scale.
Deferred client and investor sentiment
There's a much bigger version of this product that captures end-client and investor sentiment too. I deliberately scoped that out. Doing one thing well first was the only way to ship something credible. The pattern generalises later.
System Architecture
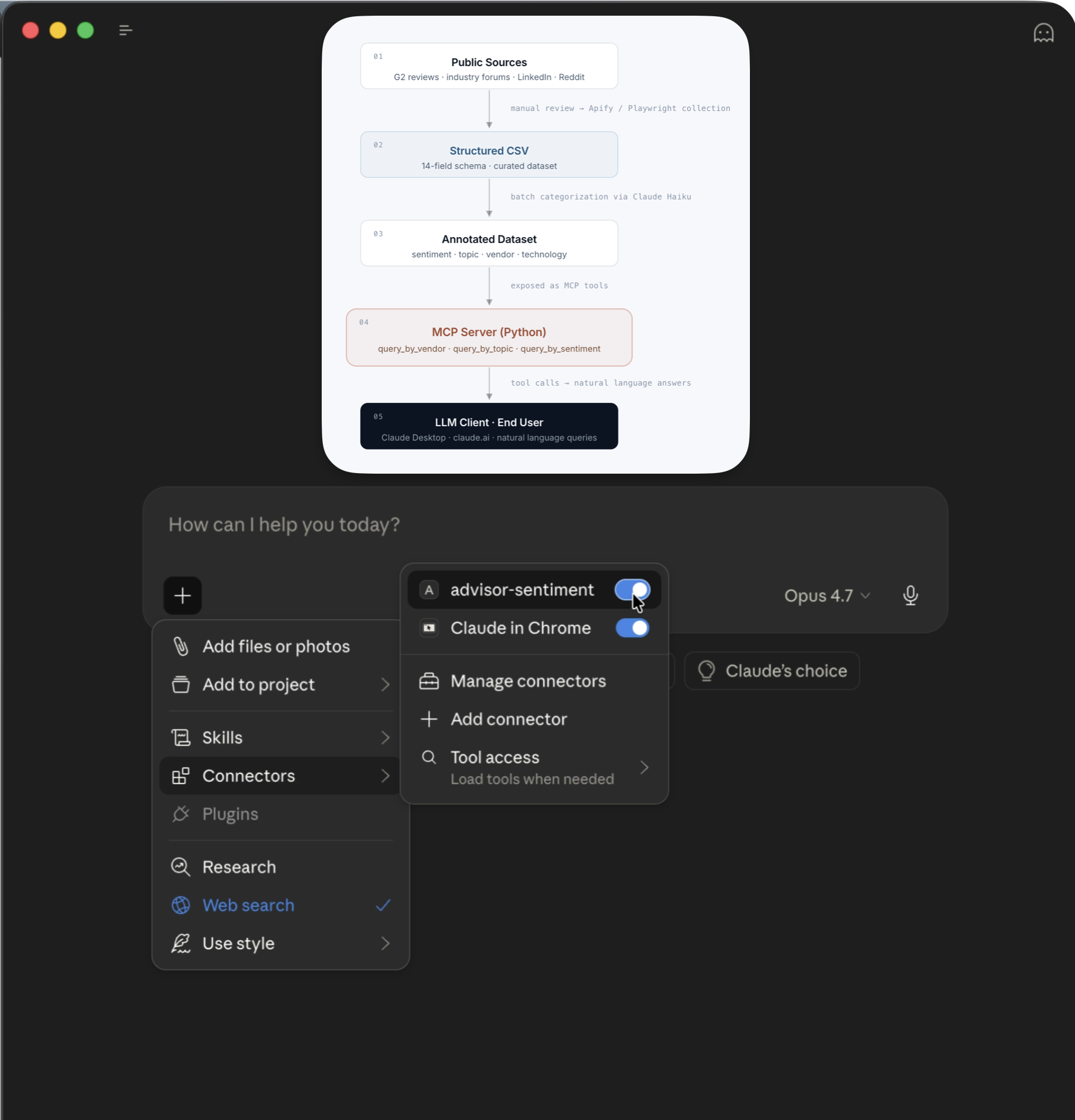
From public conversation to natural language intelligence.
The pipeline runs in one direction: collection, structure, categorization, serving. Each stage has a clear job. The MCP layer is what makes the whole thing useful — it converts a structured CSV into something any LLM can reason over in natural language, in the tool the buyer is already using.
Why MCP, Not a Dashboard
The tool they already use.
Building a dashboard would have been the obvious move. It would also have been the wrong one. A dashboard is a new tool the buyer has to learn, log into, and trust. An MCP server extends the tool they already have open — Claude — and the reasoning happens live in front of them. That changes the demo, the credibility, and the unit of distribution.
The reframe — MCP changes the unit of distribution from a tool you build to a capability inside the tool they already use. That changes the demo, the credibility, and what a small operator can ship credibly.
Live Demo
Seeing the difference live.
Side-by-side: Claude on its own gives a training-data answer that sounds right but isn't sourced. Claude with the MCP connected calls into the annotated dataset and returns specific, current intelligence the buyer can act on.
Demo: side-by-side comparison of Claude with and without the Advisor Intelligence MCP connected
The same query, two answers
Technical Highlights
Where the work actually lives.
The interesting parts of this project aren't the components anyone would expect. Most of the engineering went into the schema, the codebook, and the protocol layer — not the scraping or the model.
The Schema
Fourteen fields. Five groups.
Every field exists because a specific query pattern needs it. Together they convert messy public conversation into structured intelligence.
Why the schema is the moat — Anyone can scrape a review site. The defensible work is deciding which fourteen fields make public conversation queryable, and holding that contract steady while everything downstream evolves.
What I Learned
Lessons that outlasted the project.
MCP changes the unit of distribution
Before this, I would have defaulted to "build a UI" for any data product. MCP reframes that. The unit isn't a dashboard anymore — it's a capability you plug into the LLM the buyer already uses. That's a deeper shift than it sounds.
The schema is the product
Everything I cared about — query speed, categorization accuracy, demo credibility — was downstream of schema quality. I spent more time defending schema decisions than writing code, and the project was better for it.
Validation-first discipline pays off late
The temptation to skip ahead and build the dashboard was real every week. Resisting it kept the project tight enough that I could rewrite pieces without it falling apart. Validation discipline is the only thing that lets you change your mind cheaply.
Near-zero LLM cost changes what's viable
Batch classification at $0.40 per 1,000 reviews puts entire product categories within reach that weren't viable two years ago. The economics of structured-intelligence products have moved — most of the market hasn't caught up to that yet.
Where This Goes
I built a pattern, not just a project.
The MCP-as-intelligence-layer pattern generalises well beyond wealth-tech. Anywhere there's public conversation with structure waiting to be extracted, the same architecture applies. Wealth-tech was the first vertical because I know it best. It won't be the only one.
Next Steps
From a vibe to an instrument.
The first demo worked — but it worked on me, asking questions I already knew the data could answer. The next phase isn't more data or a nicer dashboard. It's hardening the labeling layer until "the LLM said 23%" becomes "23%, measured this way, stable to within this margin." The first is a vibe. The second is an instrument. The whole pitch is rigor a Cerulli-tier buyer can trust, and that can't rest on vibes — so everything downstream waits until this layer is defensible.
Write the codebook
Define what every label means: positive vs. mixed vs. negative, intensity 1 vs. 2 vs. 3, each with two or three anchor examples pulled from real reviews. The value is in the hard cases — praise undercut by fury at one feature, a calm factual complaint, sarcasm — and writing down how each resolves. This is the document a researcher asks for when they say "what's your methodology," and it forces decisions the LLM has been making silently.
Re-label against it
Feed the codebook into the LLM as explicit instructions and re-run all 789 reviews. The labels now reflect a stated scheme instead of an implicit one — the same data, but answerable for.
Measure self-consistency
Label 100 reviews twice on separate runs with the codebook in place and measure how often the two runs agree. 90%+ is a defensible sentence in front of a buyer. 75% means the numbers aren't stable yet — discovered cheaply and privately — and the codebook gets tightened on exactly the cases that disagreed. The only losing move is not measuring.
Add an independent human check
Hand-label 50 reviews blind, without looking at the LLM's answers, then compare. Self-consistency only proves the LLM is repeatable; human-vs-LLM agreement is the number researchers actually respect. Fifty reviews is an evening of work and a materially stronger claim.
Then expand and build the time-trend
Only after the labeling layer is something I can defend: widen vendor coverage and build the time-trend centerpiece. Everything downstream inherits its credibility from this layer, so it gets built last — not first.
The Takeaway
Public conversation, served as intelligence.
I built this because the research gap was real, the technical path was clear, and the economics had quietly shifted in favour of small operators. The MCP pattern is a template for turning public conversation into private intelligence — without building another dashboard.